Sharing below the overall technical architecture (or the data-flow) for Finverve.
Its pretty basic and simple. It involves 4 steps
- Discover - Find fintech updates from a wide variety of sources. Cast a wide net
- Process - Get content, summarize, categorize, annotate the content
- Map relevancy - score each content to individual user's preference. Reduce noise.
- Generate Post - craft a unique post for the choices of news + storyline + user's voice (WIP)
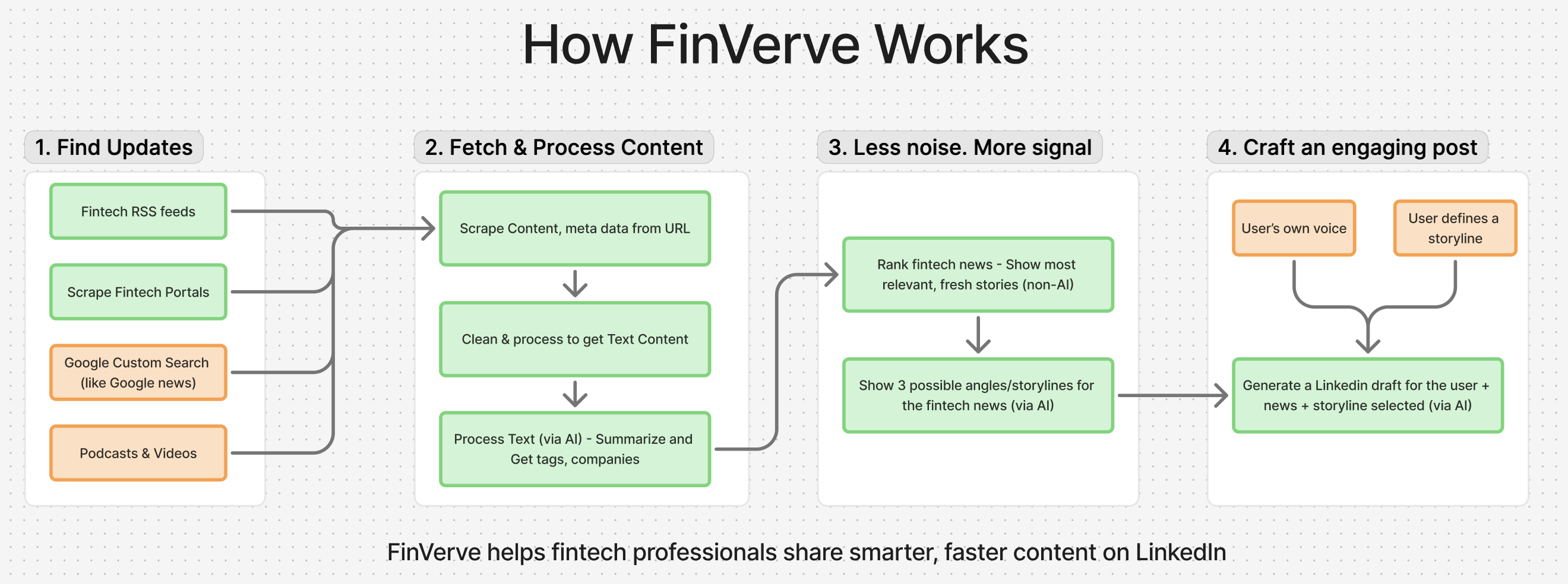
As is obvious, the step 1 is the most critical one. If we fail to get the most relevant updates, the platform will not be adding any value.
For step 1, started with RSS feeds as they are the easiest to build. Yet surprisingly most business news sites and fintech portals do not support RSS feeds now. And it is now increasingly clear that one would need to shift quickly to Google's Custom Search via APIs.
The step 3 is where the GenAI magic really starts showing up. With just the summary of an article, we are able to generate 14 unique storylines (2 for each of the 7 archetypes).
Currently, we do not use any sophisticated ML models for ranking. Though we are learning from each action that user is taking on the list of posts.
Two key things pending in step 4 - letting user's write a storyline of their own choice and the option for the user to share their own unique voice (by sharing their last x Linkedin Posts). This is still under testing and am excited about the delta impact it delivers in the uniqueness of the draft generated.
Stay tuned for the next version - where we switch to Google Custom Search and allow users to bring their own voice & storylines.
---------------------------
Also Read; Why I built FinVerve | What is FinVerve